
先說結論
嗯... `robots.txt`。它基本上就是一個... 訊號。一個放在網站根目錄的純文字檔。 告訴搜尋引擎的爬蟲,哪些地方「不建議」你來逛。它不是一道牆,更像一個「請勿打擾」的牌子。就這樣。
很多人把它想得太複雜,或用錯地方。重點是,它管的是「爬取 [crawling]」,不是「索引 [indexing]」。這兩件事不一樣。
一個常見的誤會:以為擋了就不會被索引
常常有人問,為什麼我在 `robots.txt` 裡 `Disallow` 了一個網址,結果它還是出現在 Google 搜尋結果裡?
嗯,這就是那個關鍵的誤解。`Disallow` 只是告訴 Googlebot 不要去「爬」那個頁面。但如果網路上有其他地方連結到你那個被封鎖的頁面,Google 還是會知道「喔,有這個網址存在」。
結果就是,Google 可能還是會把這個網址放進索引。但是因為它沒去爬,所以不知道頁面內容是什麼。搜尋結果上就會顯示一個光禿禿的網址,下面可能寫著「因 robots.txt 的設置,我們無法提供此結果的說明」。這其實更尷尬。
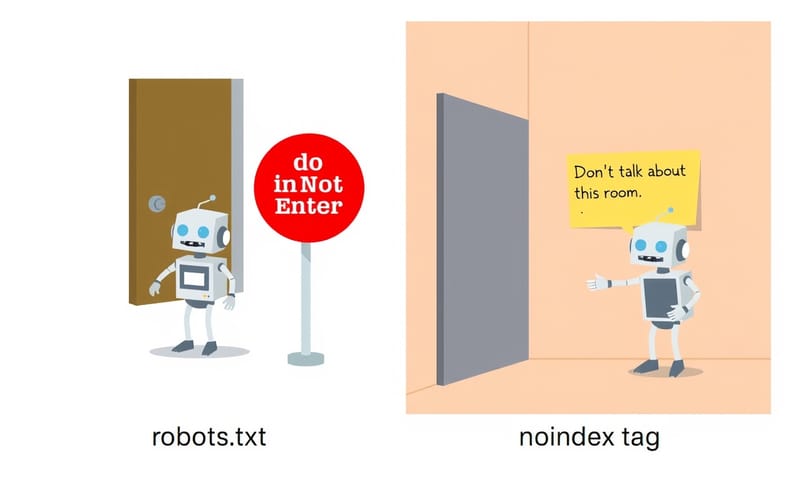
所以,千萬記得,`robots.txt` 不是用來保護隱私或敏感內容的工具。 真的不想被索引,要用 `noindex` meta 標籤才對。
怎麼做:基本語法與規則
這個檔案很簡單。就是用記事本之類的工具,寫幾行字,然後存成 `robots.txt`(全部小寫),放在網站的根目錄下。 比如 `example.com/robots.txt`。
裡面基本上就是一組一組的規則,每一組包含兩個部分:`User-agent` 和 `Disallow` 或 `Allow`。
| 指令 | 我的理解(口語版) |
|---|---|
User-agent |
指定這條規則是給哪個爬蟲看的。* 就是指所有爬蟲。也可以指定 Googlebot 或 Bingbot。 |
Disallow |
就是叫爬蟲「不要來這裡」。後面接的路徑,比如 /private/,就是禁止爬整個 `private` 資料夾。 |
Allow |
這個比較特別,通常跟 Disallow 搭配。比如你封了整個資料夾,但想開放裡面某個檔案,就可以用 `Allow`。Google 和 Bing 的爬蟲會看這個。 |
Sitemap |
嗯,這個很好用。在檔案最後面加上你網站 sitemap 的網址,可以幫助爬蟲找到你所有的頁面。 雖然你在 Search Console 也會提交,但寫在這裡,其他搜尋引擎也看得到。 |
一個最簡單的範例,允許所有爬蟲爬所有東西,但建議附上 sitemap:
User-agent: *
Disallow:
Sitemap: https://www.yourdomain.com/sitemap.xml
如果想禁止爬取 `wp-admin` 和 `wp-login.php` 這類後台頁面,可以這樣寫:
User-agent: *
Disallow: /wp-admin/
Disallow: /wp-login.php
情境變體:不同情況下的寫法
有時候會需要一些比較進階的寫法。比如說,用萬用字元 `*` 或結尾符號 `$`。
- 想封鎖所有帶有 `?` 的參數網址:
這在電商網站很常見,用來避免爬蟲浪費資源在排序、篩選的結果頁上。User-agent: *
Disallow: /*?* - 想封鎖特定檔案類型,例如 .pdf:
User-agent: *
Disallow: /*.pdf$
這裡的 `$` 符號代表網址的結尾,確保只封鎖以 `.pdf` 結尾的網址。
限制與地雷:千萬別這樣做
有幾個坑,很多人都會踩。
- 用 `Disallow` 來 `noindex`:這是最大的錯誤。前面說過了,擋了爬取,Google 反而沒機會看到你頁面上的 `noindex` 標籤,結果可能還是會索引那個網址。 正確做法是,讓 Google 爬,然後在頁面的 HTML `` 裡加上 ``。
- `Crawl-delay` 指令:這是一個舊的指令,用來建議爬蟲每次抓取的間隔秒數。 以前有些文章會教這個,但重點是,Googlebot 現在已經完全不理會這個指令了。 如果你的伺服器真的撐不住,應該從伺服器效能本身去改善,或者去 Google Search Console 設定。 其他像 Bing 可能還會參考,但對 Google 無效。
- 大小寫搞混或放錯地方:檔案名必須是 `robots.txt`,全部小寫。 必須放在根目錄。如果放在子目錄,它是無效的。
最後,寫完之後,一定要去 Google Search Console 的「robots.txt 測試工具」檢查一下語法有沒有錯,以及你的規則是不是如預期般運作。 這個步驟可以省掉很多未來的麻煩。
審核清單(簡式)
每次修改 `robots.txt` 之後,快速檢查一下:
- 檔名是 `robots.txt` (全小寫) 嗎?
- 檔案是放在網站的根目錄嗎?(例如 `domain.com/robots.txt`)
- 檔案格式是 UTF-8 純文字檔嗎?
- 語法有沒有拼錯?(例如 `Disallow` 寫成 `Disalow`)
- 有在 Google Search Console 測試過嗎?
- 是不是不小心把重要的 CSS 或 JS 檔案給擋掉了?(這會影響 Google 渲染頁面,很重要)
基本上,這個檔案就是君子協議。 它是給「守規矩」的爬蟲看的。惡意的爬蟲根本不會理它。所以,不要把它當成安全工具。它只是一個管理 SEO 爬取效率的工具。
你在 `robots.txt` 遇過最奇怪的問題是什麼?或是有什麼獨門訣竅?在下面分享一下吧。


