
哈囉,大家好啊!最近在幫幾個案主看網站,發現一個超級常見、但又很容易被忽略的問題——沒錯,就是「重複內容」(Duplicate Content)。這東西聽起來很技術,但其實它對 SEO 的影響真的不能小看,特別是那種動不動就幾十萬、幾百萬頁的大型網站,簡直是災難 🫠。
今天就來跟大家聊聊,這玩意兒到底是怎麼來的,又要怎麼抓出來,還有最重要的,該怎麼解決。
先說結論:重複內容不會直接讓你被懲罰,但會害你「上不去」
很多人一聽到重複內容就嚇得要死,以為會被 Google 抓去關禁閉、直接從搜尋結果消失。老實說,沒那麼嚴重啦。Google 官方也說過,除非你是惡意抄襲、想騙排名,不然單純因為網站結構不良造成的重複內容,不會有直接的「懲罰」。
但是!問題來了,它雖然不會扣你分,卻會讓你的分數「分散掉」。 想像一下,你寫了一篇超讚的文章,結果因為技術問題,出現了三個不同網址但內容一模一樣的頁面。Google 機器人來你家逛街的時候,就傻眼了:「欸?這三篇都一樣,我到底該推薦哪一篇給用戶啊?」結果就是,原本可以集中在一篇上的權重(像是外部連結、使用者點擊之類的積分),現在被三篇瓜分掉了。 結果就是誰都排不上去,超虧的。
這還會浪費掉 Google 給你的「爬取預算」(Crawl Budget)。 簡單說,Google 每天來你網站逛街的時間是有限的,如果它花了一堆時間在逛這些重複的頁面,那真正重要的新內容可能就沒空看了,收錄自然就變慢啦。
大家是怎麼踩坑的?(很多時候你根本沒發現)
在深入研究之前,我發現很多排名在前面的文章,大多在講 canonical 跟 301 的差別,這當然很重要,但比較少提到「到底怎麼 *發現* 這些問題」,尤其是那些藏在程式邏輯裡的隱形重複。今天我們就來補足這個缺口。
重複內容的來源千奇百怪,很多時候真的不是你「複製貼上」造成的。 我整理幾個最常見的狀況:
- 技術設定的小失誤:這超常見!例如 `http` 跟 `https` 沒做好轉址,或是 `www` 跟非 `www` 版本都能連線。 對人類來說都一樣,但對 Google 來說,它們是完全不同的網址,內容卻一樣,Bingo!重複了。
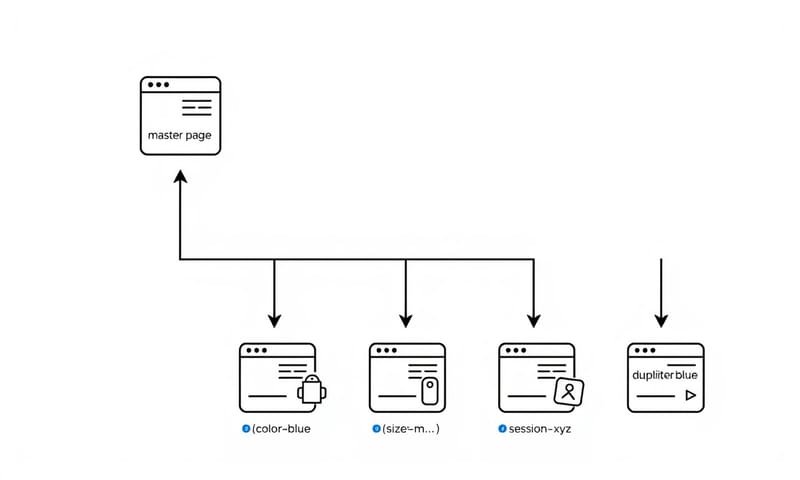
- 電商網站的惡夢:一個商品,只是顏色、尺寸不同,就產生不同網址,但產品描述幾乎一模一樣。 這在大型電商網站上,隨便都能搞出幾萬頁重複內容。
- URL 參數大亂鬥:很多網站為了追蹤使用者行為或做篩選,網址會帶上一大串參數,像是 `?session_id=...` 或 `?color=red`。如果這些參數沒有改變頁面主要內容,那 `example.com/product` 和 `example.com/product?color=red` 就會被當成重複頁面。
- 分頁、排序、列印頁:文章列表的第 2、3 頁,或是商品列表換個排序方式,甚至提供一個「友善列印」版本,這些都可能產生新的 URL,但內容大同小異。
你看,這些問題很多都是網站功能「正常運作」下的副產品,所以如果沒有特別去檢查,你可能根本不知道自己的網站正在瘋狂製造重複內容。
怎麼做?來把這些重複的傢伙抓出來!
好,理論講完了,來點實際的。要找出這些重複內容,不能只靠肉眼,我們需要工具的幫忙。這裡介紹幾種我常用的方法,從簡單到進階。
方法一:Google Search Console (GSC) — 免費又好用
這是你的第一站。GSC 的「索引 > 網頁」報告裡,有一個區塊叫做「未建立索引的原因」,你往下滑,會看到一些關鍵的提示:
- 「重複,Google 選擇的標準網頁和使用者的選擇不同」:意思是你有用 canonical 標籤指定標準頁,但 Google 不鳥你,它自己選了別的頁面當老大。 這時候你就要去檢查,是不是你的信號給得不清楚,或內容差異太小。
- 「已提交的網址未獲選為標準網址」:你透過 Sitemap 提交了這個網址,但 Google 覺得它跟另一個頁面太像了,所以選擇不收錄它。
- 「沒有 Canonical 標籤的重複項」:這最直接,就是 Google 發現了重複頁面,但你完全沒告訴它該怎麼辦。
GSC 是發現問題的起點,它會直接告訴你 Google 的看法,一定要定期檢查。
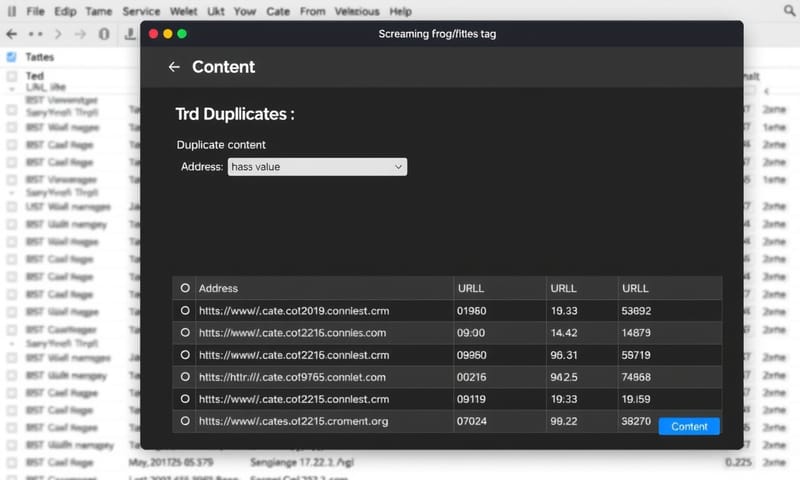
方法二:網站爬蟲工具 (Screaming Frog / Ahrefs)
Screaming Frog 是我個人的心頭好。你可以用它來爬取整個網站,然後找出潛在的重複內容。例如,你可以檢查:
- 重複的 `
` 和 `title` 標籤:
雖然不完全等於重複內容,但這通常是個很強的警訊。 - 內容相似度:有些進階功能可以讓你比對頁面內容的相似度。
- Canonical 設定檢查:一次性檢查全站的 canonical 標籤有沒有設錯、是不是指向了 404 頁面等等。
Ahrefs 的 Site Audit 工具也有類似的功能,而且介面更圖形化,對新手比較友善。這些工具是收費的,但對於管理大型網站來說,絕對是物超所值。
方法三:寫一點點 Python 小程式 (進階玩法)
有時候,重複內容的模式很刁鑽,通用工具抓不出來。例如,只有內文的某個段落完全一樣,但標題和側邊欄都不同。這時候,我就會自己寫個簡單的 Python 腳本來幫忙。
概念很簡單:用爬蟲抓取一堆你懷疑有問題的網址,然後提取出每個頁面的「核心內容」(例如,只抓 `
這聽起來很複雜,但其實現在有很多現成的 Python 函式庫可以用,幾十行程式碼就能搞定。下面是個超簡化的概念程式碼,讓你知道大概的邏輯:
# 這不是可以直接跑的程式,只是一個概念示意
import requests
from bs4 import BeautifulSoup
from difflib import SequenceMatcher
def get_core_content(url):
# 發送請求並解析 HTML
response = requests.get(url)
soup = BeautifulSoup(response.text, 'html.parser')
# 只抓取主要文章內容,忽略導覽列、側邊欄等
article_body = soup.find('article')
return article_body.get_text() if article_body else ''
def compare_similarity(text1, text2):
# 計算兩個字串的相似度
return SequenceMatcher(None, text1, text2).ratio()
# 假設我們有兩個懷疑是重複的 URL
url1 = "https://example.com/product-a"
url2 = "https://example.com/product-a?source=facebook"
content1 = get_core_content(url1)
content2 = get_core_content(url2)
similarity = compare_similarity(content1, content2)
print(f"頁面相似度: {similarity:.2%}")
if similarity > 0.9:
print("警告:這兩個頁面高度相似!")
這種方法的彈性最大,你可以自己定義什麼是「核心內容」,什麼是「相似」,完全客製化,對付奇形怪狀的重複內容特別有效。
抓到了,然後呢?解決方案大亂鬥
找出問題後,解決方案就相對單純了。最核心的兩個工具就是 `rel="canonical"` 和 `301 redirect`。 很多人會搞混,我用白話文解釋一下。
國外的 Google Search Central Blog 常常強調 `canonical` 是一個「提示」(hint),而不是一個「指令」(directive)。 但在台灣,我看到很多案例是,只要你 `canonical` 設定正確,Google 大部分時候都還是會聽話的。不過,兩邊的共識都是,`301` 是更強烈的訊號。
| 工具 | 使用時機 | 我流OS |
|---|---|---|
rel="canonical" |
頁面內容相似,但你希望兩個(或多個)網址都存在,讓使用者可以訪問。例如,不同顏色的商品頁、帶有追蹤碼的行銷活動頁。 | 這就像是在說:「嘿 Google,這幾頁長得很像,但請把所有分數都算在『這一頁』頭上。」使用者點進哪個網址,就停在那個網址,不會被跳轉。 |
301 Redirect |
舊網址「永久」失效,你想把所有使用者和搜尋引擎都導向一個全新的網址。例如,網站從 http 換到 https、網址結構改版。 | 這個比較霸道,直接跟瀏覽器和 Google 說:「別再來這個舊地方了,直接去新家!」使用者會被瞬間轉移到新網址,舊網址等於廢了。 |
noindex 標籤 |
這個頁面你不想讓它出現在任何搜尋結果裡,但你還是希望 Google 爬蟲能看到它上面的連結。例如,登入後的會員中心、內部搜尋結果頁。 | 這招要小心用!它只是讓頁面不被「索引」,但如果別的頁面 canonical 到這個 noindex 頁面,那 Google 會超混亂。通常用在處理不想被搜尋到的「薄內容」分頁上。 |

常見錯誤與修正
最後,分享幾個我在實務上看到大家常犯的錯:
- Canonical 亂指一通:有人會把 A 頁的 canonical 指向 B 頁,然後又把 B 頁的 canonical 指向 A 頁,造成無限循環。或者指向一個 404 錯誤頁面。這都會讓 Google 直接忽略你的設定。
- 用 302 暫時轉址來處理永久問題:302 轉址是「暫時的」,它不會轉移權重。如果你確定網址是永久更換,請務必使用 301。
- Sitemap 和 Canonical 打架:在 `sitemap.xml` 裡放了一堆非標準 (non-canonical) 的網址。Sitemap 應該只包含你希望 Google 收錄的標準網址。
- 以為 hreflang 能解決重複內容:對於多語系網站,`hreflang` 是用來告訴 Google「這是給不同地區/語言看的版本」,它能解決「跨國」的重複內容問題,但不能解決同一個語言網站內的重複內容。
處理重複內容是個有點繁瑣,但投報率很高的 SEO 優化工作。特別是對大型網站來說,一次成功的清理,可能會讓你的 SEO 流量有感提升。與其一直發新內容,不如回頭把家裡打掃乾淨,效果可能更好喔!
好啦,今天就先聊到這。你們的網站遇過最扯的重複內容是什麼?是因為什麼奇怪的原因造成的?在下面留言分享一下吧!🤣


