
今天要來聊聊一個網站上超不起眼,但其實又蠻關鍵的小東西:`robots.txt`。
我猜很多人可能聽過,但感覺...嗯...很技術,聽起來就像是工程師的黑話,所以就一直放著。或者你可能想過:「啊我就一個小網站,真的需要這玩意嗎?不設定會怎樣嗎?」說真的,如果你有這些疑問,那這篇剛好可以一次講清楚。
這東西不是什麼火箭科學,但搞懂它,對你的網站絕對有好處。它不像沒有 SSL 憑證那樣會直接跳出「不安全」警告嚇跑人,但它的影響是那種...靜悄悄的,等你發現 SEO 好像哪裡怪怪的、網站速度有點卡的時候,可能才想到它。
先說結論
簡單講,網站沒有 `robots.txt` 檔案,並不會馬上爆炸或被 Google 懲罰。但是,這等於是你放棄了「主動管理」的權利,把所有事情都交給搜尋引擎自己去「猜」。就像你開了一家大賣場,卻沒有任何指示牌告訴顧客「員工專用區」或「倉庫重地,請勿進入」。
結果就是,顧客(也就是搜尋引擎的爬蟲)可能會在你整個賣場裡亂逛,跑到你的辦公室、倉庫、甚至是廁所裡。這不僅會浪費他們的時間,也可能讓他們看到一些不該看的東西,還會給你添亂。所以,設一個 `robots.txt`,就是做一個清楚的指示牌,告訴爬蟲哪些路可以走,哪些路最好別來。
沒設定會怎樣?一些你可能沒想過的場景
好,理論講完了,我們來看點實際的。如果你的網站就這麼「裸奔」,完全沒有 `robots.txt`,到底會發生什麼鳥事?
場景一:你的網站後台或測試頁面,居然出現在 Google 搜尋結果裡
這大概是最常見也最尷尬的狀況。每個網站幾乎都會有一些不想給外人看的頁面,對吧?
比方說:
- WordPress 的登入頁面 (`/wp-admin/` 或 `/wp-login.php`)
- 還在開發中的測試頁面 (`/test-page-v2/` 或 `dev.yourdomain.com`)
- 使用者結帳到一半的購物車頁面 (`/cart/` 或 `/checkout/`)
- 客戶購買後的感謝頁面 (`/thank-you/`),這上面可能還有訂單資訊!
- 網站內部的搜尋結果頁,像是 `/?s=關鍵字` 這種,這對 SEO 一點幫助都沒有。
如果沒有 `robots.txt`,Googlebot 這種乖寶寶爬蟲會覺得「喔,這裡全部都可以看!」,然後就把這些頁面通通收錄進它的資料庫。哪天有個使用者不小心搜到你的後台登入頁,這不是很糗嗎?雖然有心人士本來就知道怎麼找,但你何必自己把它端到大馬路上呢?這也等於是給了駭客一個明確的攻擊目標,跟他們說:「嘿,我家大門的鎖頭在這裡喔!」

場景二:Googlebot 的「體力」被浪費在沒意義的地方
你知道嗎?Google 派來你網站的爬蟲,它的時間和資源是有限的。這個概念在 SEO 領域叫做「Crawl Budget」,也就是「爬取預算」。你可以把它想像成 Google 每天只給你網站 30 分鐘的「逛街時間」。
如果沒有 `robots.txt`,這個爬蟲可能會花 20 分鐘去逛你那些成千上萬、但內容都差不多的商品篩選頁面、標籤頁、或是前面提到的內部搜尋結果頁。結果就是,當你今天辛苦寫好一篇超棒的新文章,或是上架了一個主打新商品,爬蟲可能只剩下 10 分鐘,草草看一眼就走了,甚至根本沒時間看到它。
這會導致你的新內容非常慢、甚至不會被 Google 收錄。這對內容網站或電商網站來說,真的很傷。反過來說,有了 `robots.txt`,你就可以跟爬蟲說:「嘿,那些篩選頁、標籤頁你不用看了,直接去看我最新的文章跟商品,那才是重點!」這樣才能確保爬取預算花在刀口上。
場景三:你家伺服器被自己人搞到變慢
這點小網站可能比較無感,但只要你的網站稍微有點規模,這就是個隱形成本。爬蟲每一次爬取頁面,都是對你伺服器的一次請求(Request)。這會消耗伺服器的 CPU 和頻寬。
想像一下,一個大型電商網站,有數千個商品,每個商品頁面又有各種排序方式、篩選條件,這些都會產生大量幾乎重複的 URL。如果這些 URL 全部開放給爬蟲,等於是成千上萬的機器人不斷地來敲你家大門,雖然每次敲門的力道很小,但一直敲、一直敲...尤其是一些比較沒品的爬蟲,請求頻率超高,這會累積成可觀的伺服器負載。
結果是什麼?真實的使用者在逛你網站時,會覺得「咦,怎麼今天網站開得特別慢?」因為伺服器正忙著應付那些根本不重要的爬蟲請求。透過 `robots.txt` 擋掉這些沒意義的頁面,等於是幫你的伺服器過濾掉雜訊,讓它能專心服務真正的客人。
聽起來很麻煩,但其實超簡單,該怎麼做?
說了這麼多,你可能會覺得「天啊,聽起來好複雜」。但老實說,建立 `robots.txt` 可能是你所有網站設定裡最簡單的一項,CP 值超高。
它就只是一個純文字檔,檔名固定叫 `robots.txt`。你用任何文字編輯器,像是 Windows 的記事本或 Mac 的文字編輯就能做。
一個實用的範本
不要用網路上那些最陽春的範本,我給你一個比較實用的版本,你可以直接複製貼上,然後根據你的網站微調。
User-agent: *
# 禁止所有爬蟲爬取以下目錄
Disallow: /wp-admin/
Disallow: /wp-login.php
Disallow: /cart/
Disallow: /checkout/
Disallow: /my-account/
Disallow: /wp-content/plugins/
Disallow: /trackback/
Disallow: /feed/
Disallow: /?s=
Disallow: /*?
Allow: /wp-admin/admin-ajax.php
# 專門給圖片爬蟲的指令 (如果需要的話)
User-agent: Googlebot-Image
Allow: /wp-content/uploads/
# 告訴爬蟲們你的網站地圖在哪
Sitemap: https://www.yourdomain.com/sitemap_index.xml
稍微解釋一下:
- `User-agent: *`:這個星號 `*` 代表「所有爬蟲」,是個通用規則。
- `Disallow:`:這就是「不准進來」的意思。後面接的路徑 `/` 代表從網站根目錄開始算。我上面列了 WordPress 常見的一些路徑,像是後台、購物車、會員中心等等。`/?s=` 這個超實用,可以擋掉站內搜尋結果。`/*?` 則是擋掉所有帶有參數的網址,避免爬蟲浪費時間在篩選頁上。
- `Allow:`:就是「允許進入」。咦?我不是才把 `/wp-admin/` 整個擋掉嗎?對,但有時候 WordPress 需要讓 `admin-ajax.php` 這個檔案可以被存取,所以我們特別開一個特例。這展示了規則的彈性。
- `Sitemap:`:這行非常、非常重要。它直接告訴爬蟲你家的地圖放在哪裡。爬蟲拿到地圖後,就能更有效率地了解你網站上有哪些重要頁面,而不是自己盲目地亂闖。請務必換成你自己的 sitemap 網址。
上傳跟檢查
寫好之後,把這個檔案上傳到你網站的「根目錄」。也就是說,當你在瀏覽器輸入 `www.你的網域.com/robots.txt` 時,要能看到你剛剛寫的內容。
最後,一定要去 Google Search Console(以前叫網站管理員工具)裡面測試一下。它有個「robots.txt 測試工具」,你可以把你的檔案內容貼進去,然後輸入幾個你想檢查的網址(例如你的新文章、你的後台頁面),看看 Google 判斷是「允許」還是「已封鎖」。這樣可以避免你手殘寫錯,不小心把整個網站都給封鎖了。對,這種事真的會發生。
進階玩法:指令不是萬能的,別搞混了!
講到這裡,很多人會把 `robots.txt` 跟其他兩個東西搞混:`noindex` meta 標籤,還有伺服器密碼保護。這三者用途完全不同,搞錯了會出大事。我直接做個表格比較清楚。
| 控制方式 | 作用原理 | 優點 | 缺點 / 限制 | 最佳使用時機 |
|---|---|---|---|---|
| robots.txt Disallow | 跟爬蟲說「這個路徑你最好別來逛」。是個「建議」,不是強制命令。 |
|
|
當你想防止 Google「爬取」大量低價值頁面時,例如:
|
| noindex meta tag | 在特定頁面的 HTML `` 裡加上標籤,告訴爬蟲「這頁你看過就好,但千萬別放進搜尋結果」。 |
|
|
當頁面可以被爬、但你不想它出現在「搜尋結果」時,例如:
|
| 伺服器密碼保護 (.htaccess) | 直接在伺服器層級設定帳號密碼。沒密碼,誰都進不去。 |
|
|
當內容絕對、絕對不能外流時,例如:
|
看懂了嗎?`robots.txt` 是個「君子協定」,跟門口的「訪客請登記」牌子一樣,只對守規矩的訪客(像 Googlebot)有用。`noindex meta tag` 則是直接跟 Google 說「這頁的內容別放到你的搜尋目錄上」。而密碼保護,才是真正的「門鎖」。
這點跟我們在台灣看到的一些行銷教學很不一樣。很多文章會簡化說 `robots.txt` 是用來「禁止收錄」的,這其實不精確。Google 的官方文件(對,就是那個全英文的 `Google Developers` 網站)講得非常清楚,`Disallow` 不保證頁面不會被索引,特別是當這個被封鎖的頁面有大量外部連結指向它時。Google 即使沒爬內容,也可能因為知道它的存在而把它列進搜尋結果。所以,觀念要搞清楚。
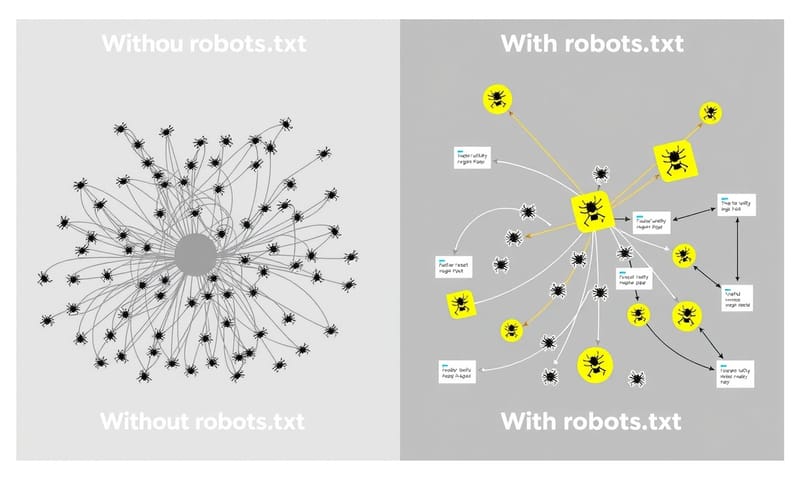
常見錯誤與修正
最後,分享幾個我實際看過或自己也踩過的坑,千萬小心。
-
手殘擋掉 CSS 或 JS 檔案:這是新手最常犯的錯。有些人想說,CSS (樣式檔) 和 JS (腳本檔) 只是版面跟功能,不是內容,把它們 `Disallow` 掉可以節省預算吧?大錯特錯!現在的 Google 是希望能「看見」使用者所見的整個畫面來評分。如果你把 CSS/JS 擋掉,Googlebot 會以為你的網站是個純文字、版面全毀的破網站,它會看不懂你的內容結構,甚至可能影響你的排名。所以,`Disallow: /wp-content/` 這種寫法是絕對要避免的。
-
把 `robots.txt` 當成資安工具:我一定要再強調一次。在 `robots.txt` 裡寫 `Disallow: /secret-financial-reports/`,這不是在保護資料,這是在昭告天下:「嘿!我的機密財務報告放在這個資料夾喔!歡迎來試試看!」惡意的爬蟲或駭客最喜歡掃描 `robots.txt` 來找目標了。真正敏感的資料,請用前面提到的伺服器密碼保護。
-
大小寫和語法錯誤:`robots.txt` 的語法是區分大小寫的。`Disallow: /Photo/` 和 `Disallow: /photo/` 是兩條不一樣的規則。一個小小的斜線 `/` 沒加,或是拼錯字,都可能導致規則失效,甚至不小心把整個網站 `Disallow: /` 給封了。所以,用完 Google Search Console 的工具檢查絕對是個好習慣。
我自己是覺得,`robots.txt` 這東西就像是網站的交通指揮官。城市裡沒有交通警察,車子亂開好像也能動,但尖峰時刻保證塞車、路口一片混亂,意外也跟著來。花個十分鐘,請一個指揮官來幫你疏導車流,告訴大家哪裡能走、哪裡該慢、哪裡是單行道,整個交通不就順暢多了嗎?這十分鐘的投資,絕對划算。
好啦,講了這麼多。現在換你了,動手去檢查一下你自己網站的 `robots.txt` 檔案吧!可以直接在網址列輸入 `yourdomain.com/robots.txt` 看看。有沒有發現什麼意外被封鎖、或是不該開放的東西?或是有什麼頁面是你一直想擋掉但不知道怎麼做的?在下面留言分享你踩過的坑,或是一起討論吧!


