
robots.txtって、そもそも何?
うーん…まあ、一言で言うと「お願い」かな。サイトに来るクローラー、つまりロボットへの。
「ここの部屋は見ないでくださいね」「ここは入っていいですよ」って案内する感じ。紳士協定みたいなもの。 これを設定しておくと、サイトの中で優先的に見てほしいページを効率よくクロールしてもらえるようになる。結果としてSEOに良い影響があるかもしれない、ということ。
絶対的な命令じゃないから、クローラーによっては無視されることもあるけど。 まあ、Googleみたいな主要なクローラーは、ちゃんと守ってくれる。
とりあえず、基本の書き方
メモ帳とかのテキストエディタで、「robots.txt」という名前のファイルを作ることから始まる。 中に書くのは、だいたいこの3つの要素。
- User-agent: どのクローラーに対する指示かを書くところ。「*」(アスタリスク)を指定すれば「すべてのクローラー」という意味になる。
- Disallow: 「ここには来ないで」と伝えるパス。
- Allow: 基本はDisallowで禁止しつつ、「この中の、このファイルだけはOK」みたいに例外的に許可するときに使う。
例えば、WordPressサイトで管理画面(/wp-admin/)へのアクセスを拒否したいけど、その中の特定ファイル(admin-ajax.php)は許可したい、みたいな場合。
User-agent: *
Disallow: /wp-admin/
Allow: /wp-admin/admin-ajax.phpこんな感じになる。 書いたら、サイトの一番上の階層、つまりルートディレクトリにアップロードする。場所を間違えると全く意味がないから注意。
最近気になる、AIクローラーの制御
最近は、検索エンジンだけじゃなくて、ChatGPTみたいな生成AIも情報を集めるためにクローラーを動かしてる。 これが結構、サーバーに負荷をかけることもあるみたいで。
だから、AIの学習に自サイトのコンテンツを使われたくない、あるいはサーバー負荷を減らしたいなら、AIクローラーもブロックしておくのがいいかもしれない。書き方は基本的に同じ。
例えば、OpenAIのクローラー(GPTBot)をブロックするには、こう書く。
User-agent: GPTBot
Disallow: /GoogleのAI(Geminiとか)の場合は、Google-ExtendedというUser-agentを指定するみたい。 各社がUser-agent名を公開してくれてるから、それに従って書けばいい。
Googleの公式ドキュメントは「こういうルールでやってますよ」と世界中に公開してるけど、AIクローラーの対応は、各社が「従います」と表明している紳士協定の側面が強い。 特に日本のサーバー会社なんかは、負荷対策としてこの設定を推奨し始めているところもある。
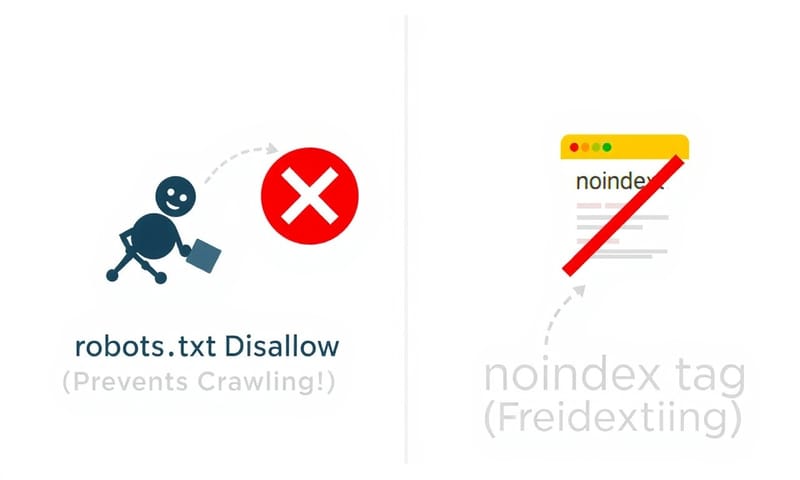
大事なのは「クロールさせない」と「インデックスさせない」の違い
ここでよく間違えるのが、robots.txtとnoindexメタタグの役割。 全然違うものだから、整理しておく必要がある。
- robots.txtのDisallow: これは「クロール拒否」。つまり、クローラーがそのページを見に来ること自体をやめてもらうお願い。
- noindexメタタグ: こっちは「インデックス拒否」。クロールはされるけど、「このページは検索結果に出さないでね」という指示。
一番やっちゃいけないのが、インデックスから削除したいページを、いきなりrobots.txtでDisallowしてしまうこと。 クローラーがページを見に来れなくなるから、そこに書かれているnoindexタグを読むこともできず、結果として検索結果に残り続けてしまうことがある。
だから、順番が大事。まずnoindexタグでインデックスから消えるのを待って、その後にDisallowでクロールを止める。
よくある記述ミス
設定は簡単そうに見えて、うっかりミスが大きな事故につながることも。
- うっかりサイト全体をブロック: これが一番怖い。 `Disallow: /` を、特定のクローラーではなく `User-agent: *` に書いてしまうと、サイト全体がクロールされなくなる可能性がある。
- CSSやJavaScriptファイルをブロック: 今のGoogleはページをレンダリングして評価するから、デザインや動きを定義しているCSSやJSファイルをブロックすると、正しく評価されなくなってしまう。基本的には許可すべき。
- テストをしない: 公開する前に、Google Search Consoleにある「robots.txt テスター」で確認するのが安全。 これで、意図した通りにブロックできているか、構文エラーはないかを確認できる。
使い分けを考えてみる【表】
じゃあ、どういう時にどっちを使えばいいのか。ちょっと自分なりにまとめてみる。
| robots.txt (Disallow) | noindexメタタグ | |
|---|---|---|
| 目的 | クロール自体をさせたくない。サーバー負荷軽減とか、どうでもいいページを見せないため。 | 検索結果に表示させたくない。内容は存在するけど、検索には不要なページ。 |
| どういうページ? | ログインページ、管理画面、パラメータ付きの無限に生成されるURLとか。 | 内容が薄いページ、サンキューページ、社内用のテストページとか。 |
| 注意点 | これだけだとインデックスされる可能性は残る。他からリンクされてると特に。 | クロールはされるから、サーバー負荷は減らない。 |
| 一番のキモ | 「来ないで」っていう玄関での声かけ。 | 「この部屋はリストに載せないで」っていう部屋の中の貼り紙。 |

結局、どうすれば?
…まあ、ほとんどの小規模なサイトなら、無理に複雑な設定はしなくてもいいのかもしれない。 WordPressを使っていれば、基本的な設定は最初から入っていることも多いし。
でも、ECサイトでパラメータ付きURLがたくさんできちゃうとか、会員専用エリアがあるとか、そういう場合はちゃんと設定した方がいい。クロールのリソースを大事なページに集中させる、という考え方。
何より、`Disallow: /` だけは、本当に気をつけて。何をしているか完全に理解するまでは、触らない方が無難だと思う。
あなたのサイトで、「このページってクロールさせるべきなのかな?」と迷っているディレクトリやファイルはありますか? よかったらコメントで教えてください。


