
AI 模型沒有什麼「永遠第一名」,比較像是「你這件事要用哪把刀」;目前最常被放在前排的通常是 GPT-5、Gemini 2.5 Pro、Claude 3(Opus/Sonnet/Haiku)、GPT-5 Turbo、o3、o4-mini、Llama 3.1 Tulu3 405B,而差別主要落在多模態能力、context window(像 Gemini 最高到 100 萬 tokens)、推理穩定度、速度與成本。
- 要全能+多模態:GPT-5、Gemini 2.5 Pro
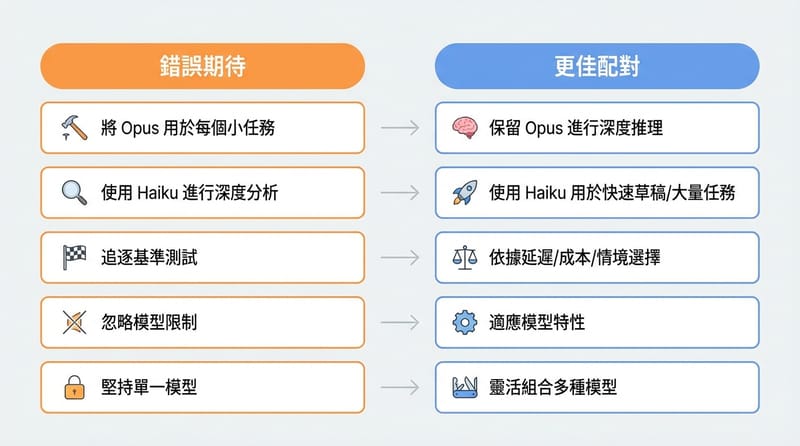
- 要推理吃重:Claude 3 Opus、o3
- 要日常商務平衡:Claude 3 Sonnet、GPT-5 Turbo
- 要快+省:Claude 3 Haiku、o4-mini
- 要開源大肌肉:Llama 3.1 Tulu3 405B
先講結論就這樣。因為排行榜看太久會頭痛,真的。
排行榜很會騙你:你要先問「我到底在解什麼問題」
AI 模型的「最好」通常不是分數最高那個,而是最符合你任務型態、預算、延遲容忍度與整合方式的那個。把聊天、寫程式、長文分析、看圖聽音、跑大量請求混在一起評分,最後只會得到一種很虛的自我安慰。
我自己會先分三種痛點:你是要「想法產出」、還是「精準推理」、還是「大量處理」?講到大量處理我就會想到那種客服工單一秒進來十幾張…你不可能拿最貴的去硬扛,財務會先扛不住。
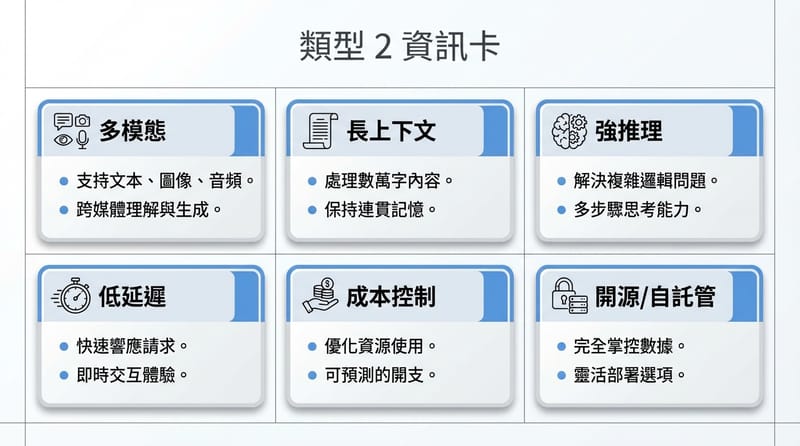
還有一個很現實的:你用得到多模態嗎?你如果只打字,模型會看圖看影片再厲害,其實跟你關係不大。除非你每天都在丟截圖問「這段錯在哪」。那就另當別論。

GPT-5:全能多模態,像把整套工具箱直接砸你桌上
GPT-5 是 OpenAI 目前最旗艦的模型,主打原生多模態(文字、音訊、圖片、影片)與更好的長上下文推理,並且在速度、脈絡掌握與事實準確度上比前代更穩。它的強項是「不用切模型」就能把多種輸入一起處理,互動會比較順。
我對 GPT-5 的感覺:它比較像「你把事情丟過去,它真的能接住」。但你要說它會不會偶爾瞎掰?AI 就是會。只是它看起來更不容易飄走,至少在複雜對話來回時,那種「前面講過的話突然忘光」的情況會少一點。
有時候你以為你要的是模型智商,結果你要的是「它不要亂演」。這句話我講得有點酸,但就是這樣。
模型越強不代表你就省事;你省事的關鍵通常是:它能不能穩定跟住你的脈絡,不要每三輪就重開機。
Gemini 2.5 Pro:100 萬 tokens 的長記憶怪物(而且是 MoE)
Gemini 2.5 Pro 的招牌是超大的 context window(最高可到 100 萬 tokens),加上 Mixture-of-Experts(MoE)架構用多個專家模組分工,讓它在處理超長文件、整本書或長影音內容時更有優勢,同時仍維持多模態能力(文字、圖片、音訊、影片)。
講到 100 萬 tokens 我就想翻白眼:因為大家會開始幻想「我把公司所有文件丟進去它就懂我公司」。醒醒。它能「吃進去」不等於它會「真的理解你那堆爛流程」。
但你如果是那種真的要把長文件、長逐字稿、很多段落一起比對的人,Gemini 這種大窗就很香。尤其你要它在同一個 session 裡維持一致性,長窗的價值才會跑出來。
在台灣的情境我會怎麼用:例如你要整理一堆政府標案文件、會議紀錄、規格書(那種 PDF 又長又亂),一次丟進去讓它抓關鍵條款、找矛盾點,這種工作其實挺像「把人逼瘋」的前置作業。交給長窗模型比較合理。
Claude 3 Opus:推理重砲,200k tokens 的耐心怪
Claude 3 Opus 是 Anthropic Claude 3 系列的高階款,強項在複雜推理、長文件分析與多步驟問題解決,context window 可到 200,000 tokens,適合拿來讀長篇內容、看大型程式碼庫或做需要連結多段資訊的判斷。
Opus 的氣質:比較像那種「你不要催我,我在想」的同事。它不一定最快,但它比較願意把事情想完整一點。
缺點也很直白:資源吃比較兇。你要把它當成每個 request 都用的萬用機器?你錢包會先哭。
Claude 3 Sonnet / Haiku:一個是穩健工班,一個是衝刺短跑
Claude 3 Sonnet 走的是速度與能力的平衡,適合日常商務:文件摘要、內容草稿、客服回覆、基本程式協助;Claude 3 Haiku 則主打低延遲與成本效率,適合高頻、短回合、快速摘要或即時互動場景。
Sonnet 就是那種「大部分事情都能做」:你丟 email 草稿、行銷文案、簡報段落,它大多不會讓你難堪。你要它做超硬推理?它也不是不行,但會有點像用小貨車載鋼筋,能載啦,但你會怕。
Haiku 的定位我反而喜歡:很多人看不起「快但不深」,但實務上你有一堆需求只是「快點給我一版能用的」。Haiku 這種就很務實。你要的是 throughput。不是哲學。
對了,講到 throughput,我突然想到台灣很多公司內網還卡得要命,模型再快也救不了你那個 VPN。好,先不講這個。
GPT-5 Turbo:256k tokens 的量產型選手(便宜一點,夠強)
GPT-5 Turbo 是偏向生產環境的平衡款,主打速度、效率與成本表現,並提供最高約 256k tokens 的 context window,適合長文件摘要、結構化輸出、商務自動化與大量穩定請求,但不一定需要 GPT-5 旗艦那種全套多模態與高成本。
Turbo 的存在感很現實:公司真的要上線、要跑流程、要接 API,最後你會回到「穩定、延遲、成本」這三個字。很無聊。也很殘酷。
你要的是一台不會動不動就「今天心情不好」的機器。Turbo 通常比較接近那個樣子。
o3 / o4-mini:一個偏跨學科答題怪,一個偏快手小鋼砲
o3 常被提到的賣點是跨領域問答表現,尤其在自然科學、醫療健康、工程與人文領域的回答能力;o4-mini 則是更小更快的取向,適合快速生成、簡短摘要、直覺型互動與不需要最深推理的任務。
我看到「醫療健康」四個字會先皺眉:因為你拿任何模型問醫療問題,都不要把它當醫師。它可以幫你整理資訊、列出你要問醫生的問題,但你要它下診斷?拜託不要。這不是保守,是自保。
o4-mini 這種小模型就很像你手機的快捷鍵:不華麗,但你一天會按一百次。用久了你反而離不開。
Llama 3.1 Tulu3 405B:開源大塊頭,405B 參數的肌肉派
Llama 3.1 Tulu3 405B 是 Meta 生態系的大型開源模型之一,405B 代表約 4050 億參數,強調指令遵循與在推理、寫作、摘要、程式任務上的基準表現,對想要自建、可控、可客製的團隊來說是重要選項,但也意味著更高的部署與運維門檻。
開源的浪漫我懂:你可以自己掌控、自己調教、自己決定資料怎麼進怎麼出。尤其有些產業就是不想把資料丟到外面去,這很合理。
但開源的代價也很實在:硬體、推理成本、MLOps、人力…你少一個環節都會卡住。你以為你在買自由,其實你在買一堆待辦事項。唉。
截圖用檢核表:選 AI 模型前先把這 12 題勾一勾
選模型這件事最常見的悲劇是:你買了最貴的,結果用法跟需求根本沒對上。你就先做這個,真的可以少走一點冤枉路。
- 1. 你的主要任務是聊天、寫作、coding、摘要、還是分析資料?(只能選一個主戰場)
- 2. 你要不要看圖、聽音、吃影片?如果沒有,多模態加成很有限。
- 3. 你一次要丟多長的內容?(幾頁文件 vs 一整本書 vs 一堆會議逐字稿)
- 4. 你需要模型「記得」前面講什麼到什麼程度?(短對話 vs 長專案)
- 5. 你更在意哪個:準確、速度、成本?三選一先選最在意的。
- 6. 你能不能接受偶爾要人工複核?如果不能,你要把流程設計成「可驗證」。
- 7. 你要不要結構化輸出(JSON、表單欄位、固定格式報告)?如果要,挑擅長結構化的。
- 8. 你會不會把它接到系統裡跑大量請求?如果會,Haiku / o4-mini / Turbo 這種就要列入清單。
- 9. 你的資料能不能出內網?如果不能,開源(如 Llama 3.1 Tulu3 405B)或自建方案就別逃避。
- 10. 你要不要讓它讀整個 codebase?如果要,context window 直接影響體驗。
- 11. 你需要多語言(含繁中)穩不穩?台灣情境這點常被忽略,然後就開始抱怨。
- 12. 你願不願意做 A/B 測試?同一份任務丟兩個模型比,10 分鐘就知道誰比較適合。
小提醒:你如果是要做企業導入,除了模型本身,還要看你用的雲端平台、權限控管、記錄留存、稽核需求。台灣這邊很多單位其實很在意「資料怎麼出去、誰看過、留多久」。這不是龜毛,是流程。
最後我想講的比較難聽:別再迷信「第一名」,你要的是可控
排行榜會變,benchmark 會變,連你今天的需求都會變。你真正要追的是:你這個工作流能不能被複製、能不能被驗證、出事時你能不能追得回來。這比「誰分數高 0.3」實在太多。
你不是在選一個神明,你是在選一個能被你管得住的工具。
好,講完又有點累。😮💨
給你一個小挑戰:挑一個你最常做的任務(例如:把會議紀錄變成待辦清單、把一段程式碼找 bug、把長文件抓出重點),用 兩個不同模型各跑一次,然後只比三件事:正確率、修改成本、回應速度。你會突然清醒。
做完你就會知道,你其實不需要「最強」,你需要「最合你」。就這樣。


