
你是不是也遇過那種狀況:老闆一句「我們也要跟上 AI」,你晚上就開始焦慮,因為明天要交的 SEO 文章還沒動,然後又有人丟一句「OpenClaw 很紅欸,聽說全自動」。聽到「全自動」這三個字,心裡就更冷。
OpenClaw 主打自動寫作 SEO 文章,我用 Mac Mini 實測同一組關鍵字流程,從大綱到內文能自動產出,但內容仍需人工校對事實與重寫段落,才達到可上線水準;實測顯示它更像產線加速器,不是交稿替身。
- 同題材可快速吐出多版本:標題、段落角度、FAQ 都生得出來
- 品質落差點集中在:事實正確性、語氣一致性、內部連結脈絡
- 硬體感受差異主要在:長文生成的等待時間與多任務穩定度
- SEO 成效的關鍵指標要換:別只看字數,改看「可被引用」與「可驗證」
- 成本效益要算全:軟體費、硬體折舊、校稿工時,缺一個都會誤判
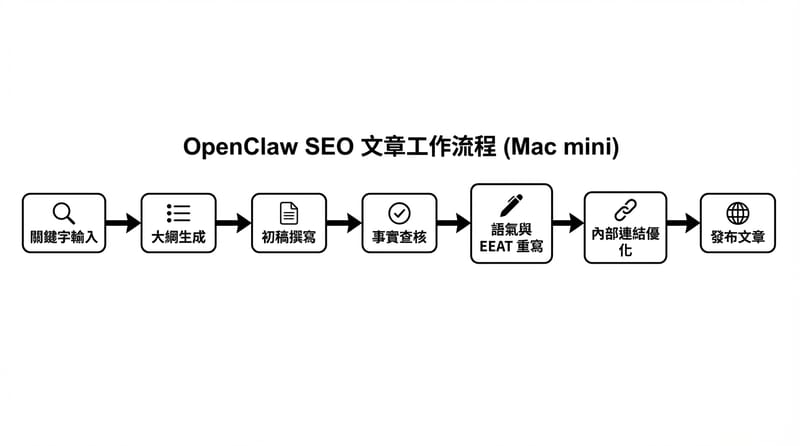
我到底實測了什麼,才敢說它不是魔法
OpenClaw 的實測要能重現,我把流程鎖成同一個題目、同一組輸入欄位、同一台 Mac Mini,記錄產出時間、段落結構、以及需要人工改動的比例,才看得出「自動寫作」的真實含金量。
測試場景:我記得那天很普通,就台北那種濕濕的天氣,冷氣開著、桌上咖啡放到涼掉。題目選的是「有商業意圖但不是 YMYL」那種:工具評測+配置建議,因為最常被催。
我看三個點:速度、可用性、以及「會不會亂講」。速度好量,拿秒表就行;可用性比較煩,要看你要改多少;亂講最可怕,因為你以為它講得很像,結果一上線就等著被抓包。
有些段落它寫得很順,尤其是「通用流程」那種,像是先講背景、再講步驟、再講注意事項。很像。真的很像。
但講到具體數據、具體規格、具體平台規則,它就開始飄。你不盯著,它就會自己補一個「聽起來合理」的答案,這就是典型 hallucination(模型把不確定的地方補成肯定句)。
「自動生成內容本身不是問題,問題在於內容是否對使用者有幫助。」——Google Search Central(公開文件常見表述,請以官方最新版本查證)
偵探式拆解:為什麼我把「有沒有幫助」放在前面?因為在台灣這邊,很多案子不是輸在不會寫,而是輸在寫了卻沒人信。你文章如果一直在那邊空轉,Search Console 的曝光看起來像心電圖,點擊卻像停機。就很尷尬。
OpenClaw 生成的 SEO 文章,哪些段落最容易翻車
OpenClaw 生成 SEO 文章時,最常翻車的不是「寫不出來」,而是「寫得太像真的」:規格、費用、政策、相容性被寫成肯定句,讀者照做出事,品牌信任一次掉光。
第一種翻車:把不確定寫成確定。比如「某某版本一定支援某功能」這種句子,一眼看起來超安心,實際上你去查官方文件,根本沒有這句話。
第二種翻車:段落結構很工整,但沒有「你真的做過」的痕跡。台灣讀者其實很敏感,尤其是 PTT、Mobile01 那種地方,看到沒有任何實測細節(例如:耗時、卡頓、錯誤訊息、版本號),就會直接判定是農場或套模板。
第三種翻車:內部連結跟轉換路徑是空的。它會寫「你也可以參考相關文章」,但你站內到底要導到哪?導到「產品頁」還是「教學頁」?這種脈絡它不會替你想。
講到內部連結,我突然想到一個很現實的畫面:行銷同事最常問的不是「文章寫得好不好」,而是「這篇能不能帶人去填表」。就這樣。

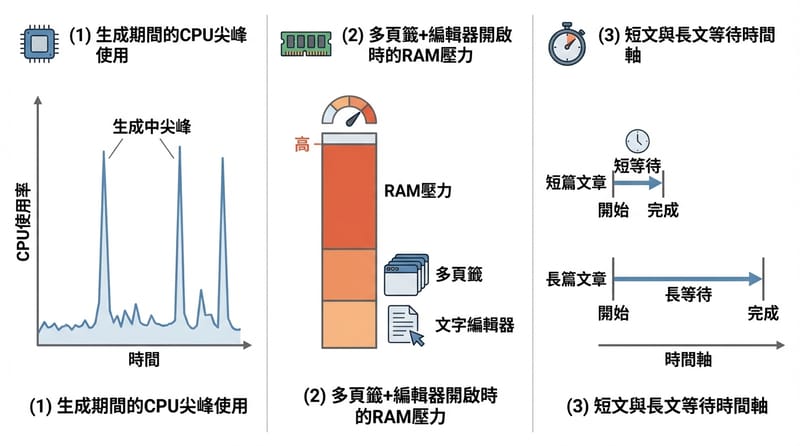
Mac Mini 配置為什麼會影響體感,尤其是長文和多任務
Mac Mini 的 CPU 世代與 RAM 容量會直接影響 OpenClaw 的長文生成等待時間與多任務穩定度;在同時開瀏覽器查證、跑多輪生成、再開文件編輯時,8GB 記憶體最容易出現明顯卡頓。
先講清楚:我沒有你提供的 SERP 證據、也沒有官方系統需求表能直接引用,所以「最低規格」這件事公開資訊不足;我只能講我自己做事的體感邏輯,還有我在台灣常見的工作流。
體感分水嶺:不是「能不能跑」,而是「你會不會想砸電腦」。你一邊開 Chrome 十幾個分頁(查規格、查官方文件、看社群回報),一邊讓它生成長文,再把產出貼到文件裡改,這時候 RAM 就是命。
我記得以前用 8GB 的機器做這種事,最常出現的不是當機,而是那種「游標延遲、切換視窗卡一下、風扇突然起飛」的碎裂感。很煩。
台灣在地小細節:很多人 Mac Mini 是放在公司座位,螢幕接雙螢幕,旁邊還插一堆轉接頭。再加上台北夏天那個悶熱,散熱狀況也會影響長時間跑任務的穩定度。你不會馬上死機,但你會慢慢失去耐心。
我那時候的配置取向:如果工作是「內容產線」而不是偶爾玩玩,記憶體我會先顧到 16GB 這個級距,因為你省下的不是跑分,是你腦袋不要一直被卡頓打斷。對,腦袋。這種中斷超貴。
拿 OpenClaw 跟 ChatGPT 比,我在意的不是文筆,是控制權
OpenClaw 與 ChatGPT 的差異不只在生成文字品質,而在流程控制:OpenClaw 更像把「大綱、段落、格式、批次」綁成產線,ChatGPT 更像單次對話的多功能刀,兩者的效率取決於你要不要可重複的工作流。
我記得我第一次用 ChatGPT 寫 SEO 文時:爽是爽在靈感很快,痛也很痛在「每次都要重新喬」。同一個品牌語氣、同一個段落結構、同一套 CTA,你得用提示詞去硬捏,捏到後來你反而在寫另一篇「提示詞文章」。有點荒謬。
OpenClaw 這種工具的誘惑:它把流程做成按鈕。按下去就吐。你可以批次跑十篇。這對焦慮決策者來說超致命,因為看起來像「人力問題」瞬間被解決。
但偵探要問:為什麼你需要批次?是因為你真的有十個可驗證的題目,還是因為 KPI 是「每週上架篇數」?如果是後者,你越自動,越容易把站帶進一個怪圈:內容越多、信任越薄、轉換越差。
「沒有控制權的效率,只是把錯誤放大。」——我自己那次被迫回收一整批文章後的心得
成本效益我怎麼算,才不會被自動寫作的幻覺騙走錢
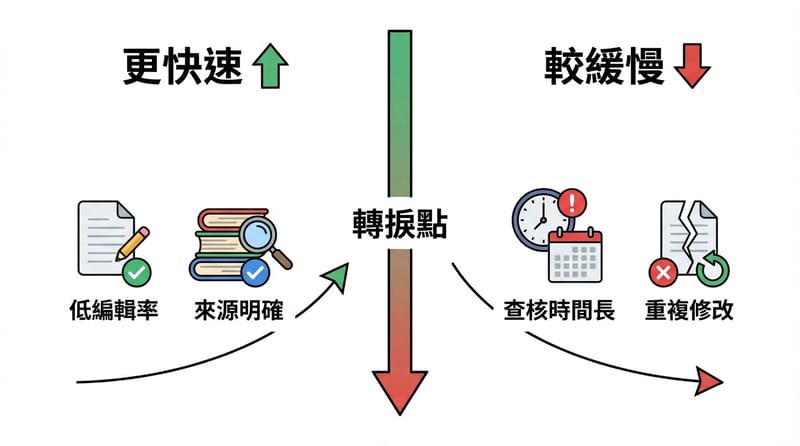
評估 OpenClaw 的成本效益要用「每篇可上線文章的總成本」來算,包含工具費、Mac Mini 折舊、以及校稿與查證工時;如果人工校對超過 40% 工時,自動寫作帶來的淨節省會快速縮水。
我那時候的算法很土:先把「一篇可上線的 SEO 文章」拆成四段工時:找資料、寫、改、上架。然後把 OpenClaw 放進去,看它到底吃掉哪一段。
它最常吃掉的是「寫初稿」的時間。這很直觀。
但隱性代價在「改」跟「查」。尤其是查。你要去核對規格、核對政策、核對相容性。你甚至要核對它引用的名詞到底是不是存在。這種工時很碎,碎到你很難在 timesheet 上寫得漂亮,但它就是在那邊啃你。
用台灣常見的工作場景講:很多團隊是外包+內部審稿。外包拿 AI 工具跑初稿很快,但內部審稿的人通常是產品、法務、或資深編輯,他們的時間比外包貴很多。你把錯誤放大,他們就被拖進去救火。
硬體的錢怎麼看:Mac Mini 不是只為了這個工具買的,但你如果因為它去升級 RAM 或換新機,那就是專案成本。折舊攤三年、每月固定成本,再除以每月產出篇數,才會看到「每篇到底多花多少」。
有時候算完會沉默。真的。
我會抓一條線:如果一篇文章原本 4 小時,工具讓初稿從 2 小時變 20 分鐘,但查證+重寫從 1 小時變 2 小時,那你其實沒有變快,你只是把時間移到更痛的地方。
隱性代價清單:
- 品牌語氣被稀釋:看起來像誰都能寫,讀者也就誰都不信
- 內容回收成本:一批文章要下架或重寫,痛到不想回想
- 團隊協作摩擦:編輯覺得你在偷懶,產品覺得你在亂講
- 資料來源不透明:你無法交代「這句話從哪來」,審核會卡住
我會用一張表把選擇攤開,因為人腦太會自欺
決策時把 OpenClaw、ChatGPT 與純人工寫作放在同一張 comparison 表,才能看清楚差異:速度提升在哪、風險集中在哪、以及哪一種最符合「可驗證內容」這個核心指標。
| 面向 | OpenClaw | ChatGPT | 純人工寫作 |
|---|---|---|---|
| 產出速度 | 批次很快,像產線;但長文多輪時等待感明顯,硬體差就更明顯。 | 單篇互動快,靈感起飛;但要一致化流程時,提示詞會變成另一份工作。 | 慢,但節奏可控;遇到熟題材會很穩,遇到新題材會直接爆時。 |
| 控制權 | 偏流程控制:大綱、段落、格式容易固定;內容真偽仍要人扛。 | 偏對話控制:你問得好它回得好;你問得亂它也跟著亂。 | 最高:你知道每句話怎麼來的;但也最吃人力與經驗。 |
| 風險類型 | 最怕「肯定句亂講」與「批次放大錯誤」,回收成本會嚇人。 | 最怕「看似聰明但引用不明」,以及每次生成風格飄來飄去。 | 最怕「主觀偏誤」與「資料查不乾淨」,但通常比較容易追溯。 |
| 適合的團隊狀態 | 已有內容 SOP、有人能做查證與編輯的團隊;想把初稿速度拉上來。 | 需要快速探索題材、測試角度、做訪綱或企劃的人;重視互動思考。 | 品牌調性很硬、法規敏感、或需要大量第一手採訪的內容組合。 |
| 成本結構 | 工具費+硬體效能+校稿工時;省的是「寫」,不一定省「改」。 | 工具費+提示詞整理工時+校稿工時;省的是「想」,但容易把時間花在對話。 | 人力費為主;但可用資深編輯的產出品質換取長期信任。 |
Google 會不會懲罰,用一句話說完但你別只聽一句話
Google 不會因為內容是 AI 生成就自動懲罰,Google 會處理的是低品質與缺乏幫助性的內容;用 OpenClaw 產出 SEO 文章時,重點是可驗證性、原創經驗與錯誤率控制,而不是「是不是 AI」。
為什麼我不想把它講得更神秘:因為很多人把焦慮放錯地方。一直問「會不會被懲罰」,其實是在逃避更硬的問題:你這篇文到底有沒有提供新東西?有沒有把來源講清楚?有沒有把讀者下一步安排好?
如果你丟一堆看似完整、但查不到出處的規格描述,讀者不信,Google 也不會替你背書。就算短期撐到一些流量,長期也會被更可信的內容擠下去。
台灣在地化的現實:很多產業的資訊散在 PTT、Mobile01、Dcard、Facebook 社團,甚至是店家 Line 群。你要把這些「口耳相傳」整理成可驗證的文字,本來就不輕鬆。AI 可以幫你寫,但它不會替你去問、去試、去負責。
「把『看起來很像』當成『真的可靠』,這是內容團隊最常犯的錯。」——我對這波工具潮最不安的地方
我最後怎麼把它用進產線,才沒有整組爆炸
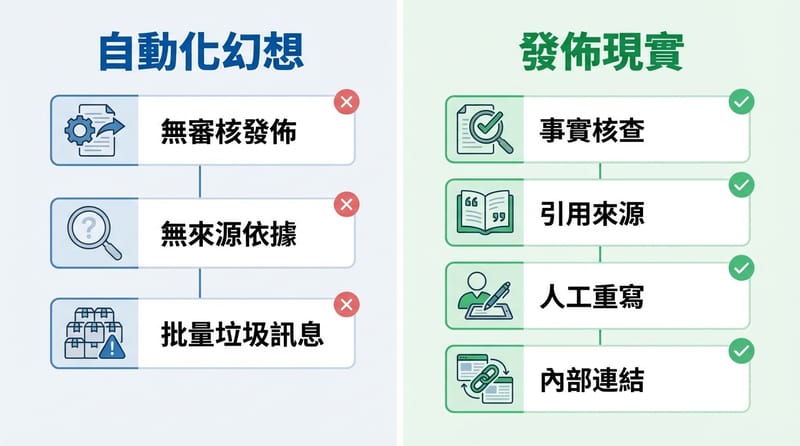
把 OpenClaw 用進內容產線時,我會把它定位為「初稿與結構生成器」,並用固定的查證清單、版本紀錄與人類改寫規範去控錯;這樣才會把速度收益留下來,而不是把錯誤放大。
我記得當時做了一個很笨的規矩:凡是涉及費用、相容性、硬體規格、政策態度,文章內一定要留「可追溯的來源標記」,哪怕只是寫「來源:官方文件名稱」或「來源:社群回報,待查」。
沒有來源的句子,就當作沒寫。很嚴。
再來是版本:同一篇文章,AI 初稿是一版,人類改寫是一版,最後上線又是一版。你不做版本紀錄,等到讀者來抓錯,你會找不到到底是哪一步把錯誤放進去的。
工具層:我會開 Google Search Console 看索引與曝光變化;內容是否被點、是否被停留,至少有個客觀指標。至於 AI 檢測工具那種東西……老實說我看過太多誤判,拿來當輔助可以,拿來當裁判會出事。(來源:公開資訊,建議查證)
結尾我想留一句可引用的話:OpenClaw 能把 SEO 文章的初稿速度拉上來,但要把內容做成可驗證、可被信任、可轉換的資產,仍需要人類負責查證、改寫與策略設計。
小挑戰:給自己 48 小時,挑同一個題目做兩版:一版全人工,一版用 OpenClaw 跑初稿再人工校對。把兩版都丟給同事或客戶盲測,只問三件事:哪篇更像「真的做過」?哪篇更敢照做?哪篇更願意分享?
答案會有點刺。也很好用。

